Aktiecase.com
Bloggen
Bokhyllan
Om Aktiecase.com
Mina Topp 5 Verktyg för att Bevaka Bolag
Hur du bevakar, samlar och lyssnar in noga på dina bolag
Apr 10, 2024
Jakob Johannesson
Mentala modeller och nya sätt att tänka
Poor Charlie’s almanack har påverkat hur jag tänker, här är några reflektioner på hur mitt tankesätt förändrats
Feb 25, 2024
Jakob Johannesson
Bokhyllan: Nytt kapitel på Aktiecase.com
Digital version av mitt biblotek. Se navigationen!
Feb 9, 2024
Jakob Johannesson
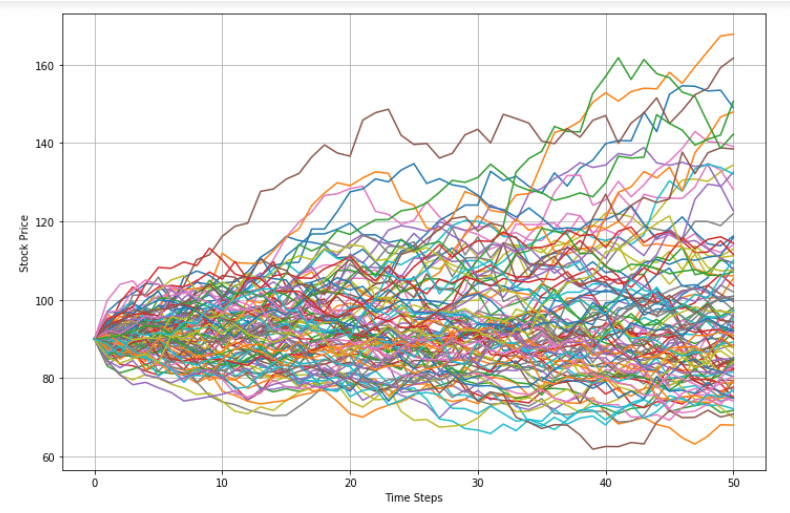
Monte Carlo Simulation serverless using Python Shiny Live + Code!
Monte Carlo Simulations are powerful. Using Shinylive with Python, you can leverage web assebely to distribute your insights with users who do not have the possibility to access your dynamic analysis otherwise.
Jan 19, 2024
Jakob Johannesson
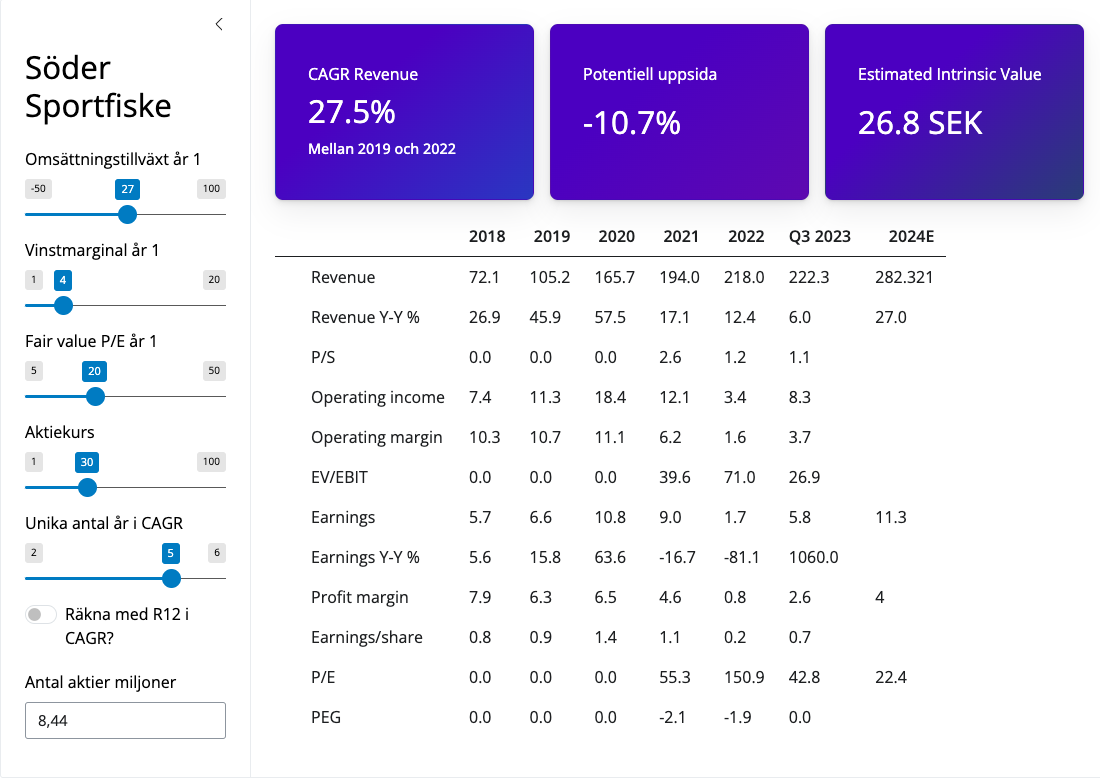
How to create an Interactive Fundamental Valuation
Interactive valation tool using Shinylive with Python
Jan 12, 2024
Jakob Johannesson
Aktiecase Provide it
Rockad i ägarlistan för konsultbolaget Provide it
Jan 5, 2024
Jakob Johannesson
Aktiecase Avtech
Ett intressant aktiecase! Mitt största innehav för en anledning, läs här varför
Dec 30, 2023
Jakob Johannesson
Aktiecase Volati
Starka ägare, fin industri, bra nischer, grymt track record - är Volati värt att ha i portföljen?
Sep 15, 2023
Jakob Johannesson
Aktiecase Sleep Cycle
Sleep cycle är den ledande sömnmonetoreringsappen i världen med sina 881k användare, stabila intäker, starka nettokassa och kapitalstarka ägare. På baksidan av Sleep Cycle lurar väldigt hög churn, svag kapitalallokering och ett nettoutflöde av kunder, dels drivet av högre priser. Antagligen siktar största ägarna på att köpa ut bolaget från börsen inom ett år, frågan är till vilket pris.
Sep 5, 2023
Jakob Johannesson
Aktiecase Truecaller
Grundarduo som äger mycket och är opererativa i verksamheten, stor fisk i liten växande nisch, indisk exponering samt en svacka i tillväxten. Är Truecaller värt att plocka upp i portföljen?
Aug 29, 2023
Jakob Johannesson
Avtech: Ett bolag med hög potential i flygbranschen
Avtechs produkter verkar flyga
May 7, 2023
Jakob Johannesson
Teqnions årsstämma 2023
Teqnion tuggar på och mitt intryck från bolagets nyckelpersoner är bra.
Apr 22, 2023
Jakob Johannesson
Imint: En ledande aktör inom videoanalys
Videostabiliering är inte den mest stabila marknaden att vara på. Uppdaterad den 28e augusti
Apr 9, 2023
Jakob Johannesson
Aktiecase - Raketech
Raketech, affiliatebolaget inom iGaming som går från klarhet till klarhet
Jan 13, 2023
Jakob Johannesson
Aktiecase - Bahnhof
Mättad privatmarknad och trött molnverksamhet. Vad är det som ska rädda Bahnhof från stagnering?
Dec 19, 2022
Jakob Johannesson
Vad jag äger och varför
Här delar jag med mig av min portfölj och vad jag ser - Gör din egen analys
Nov 3, 2022
Jakob Johannesson
Motivation, discipline and habits
Raw thoughts on hunger, motivation, discipline and habits
Nov 2, 2022
Jakob Johannesson
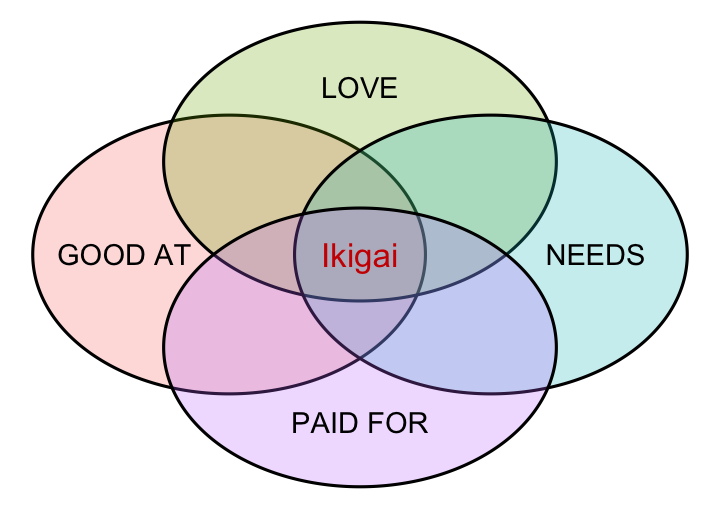
How to create a Venn Diagram in R
Short guide on how to create a Venn Diagram with code provided
Oct 24, 2022
Jakob Johannesson
Bolagsanalys av Wonderful Times Group
Wonderful Times Group är ett superlitet bolag, finns det något att hämta här?
Aug 12, 2022
Jakob Johannesson
Aktiecase - Teqnion
Teqnion har troligen en av de bästa möjliga uppsättningen av vd och finanschef jag sett
Aug 10, 2022
Jakob Johannesson
Aktiecase - Devport
Devport är en teknikkonsult som fokuserar på fordonsindustrin.
Jun 24, 2022
Jakob Johannesson
How to deploy a Streamlit app
Deployment is a crucial part of delivering value to your stakeholders, in this guide I will show you how to do it.
Jun 15, 2022
Jakob Johannesson
How to create a Streamlit app in VS Code
Streamlit is a pure python framework which allows you to create simple and easy dashboards for your team.
May 31, 2022
Jakob Johannesson
Man’s Search For Meaning av Viktor Frankl
Vad är egentligen meningen med allt?
May 30, 2022
Jakob Johannesson
Aktiecase - SBB
Kritiserad ledning, starkt ägande, förvirrande finansiell struktur, hög variation i värdering. Var är vi påväg?
May 24, 2022
Jakob Johannesson
Bayesian A/B testing in R
Using A/B testing in R with the bayesAB package
May 13, 2022
Jakob Johannesson
Matplotlib demo
Using matplotlib in Quarto
May 11, 2022
Jakob Johannesson
How to fetch information from a website in python
Is Playwright any better than Selenium?
May 6, 2022
Jakob Johannesson
Creating maps in R
Here we will dive deeper into the maps
May 6, 2022
Jakob Johannesson
DCF med hjälp av Börsdata API
Denna gång hjälper jag dig komma igång med en DCF analys med hjälp av Börsdata API och mer specifikt de nyckeltal som finns där!
Oct 10, 2021
Jakob Johannesson
Anslut till Systembolagets API med R
Systembolagets API kan vara en spänannde första plats att utforska. Anslut till Systembolagets API med R
Jul 1, 2021
Jakob Johannesson
Nyckeltal genom Börsdatas API
Börsdatas API med det statistiska programmeringsspråket R och Rstudio. Vill du komma igång med att använda dig av automatiserad analys?
Nov 11, 2020
Jakob Johannesson
Hur använder jag Börsdatas API?
Börsdatas API med det statistiska programmeringsspråket R och Rstudio. Vill du komma igång med att använda dig av automatiserad analys?
Feb 9, 2020
Jakob Johannesson
How to fetch information from a website in python
Is Playwright any better than Selenium?
Invalid Date
Jakob Johannesson
No matching items